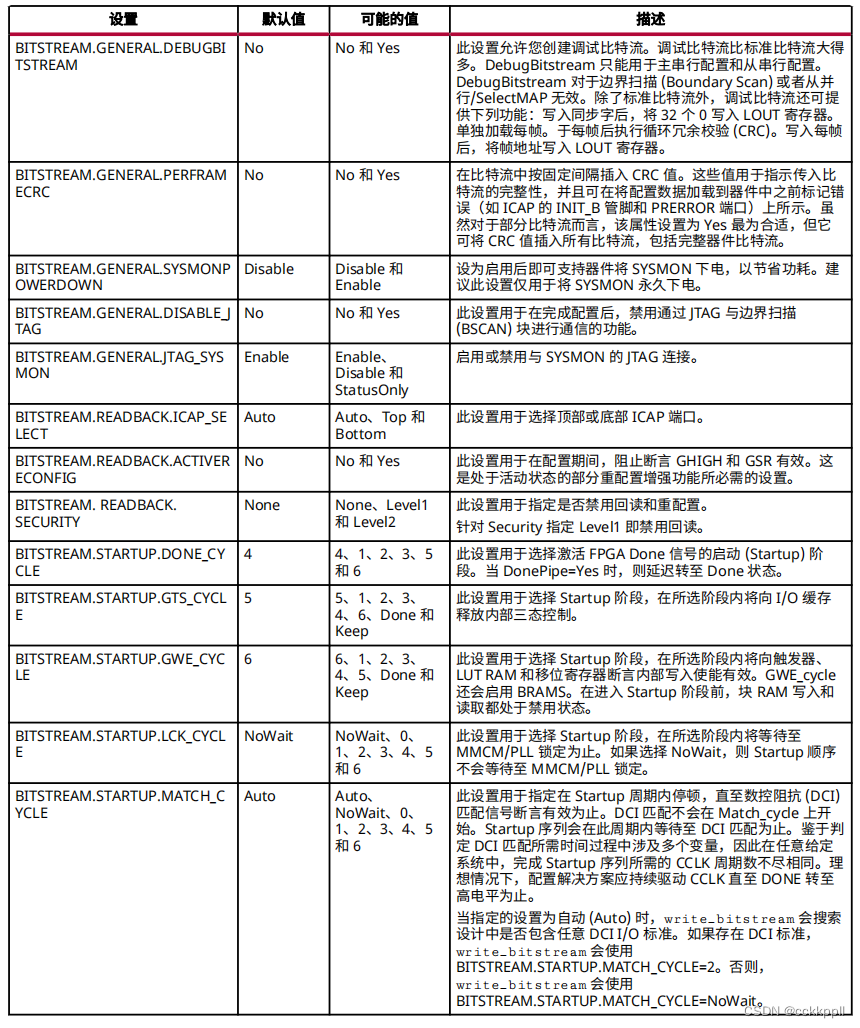
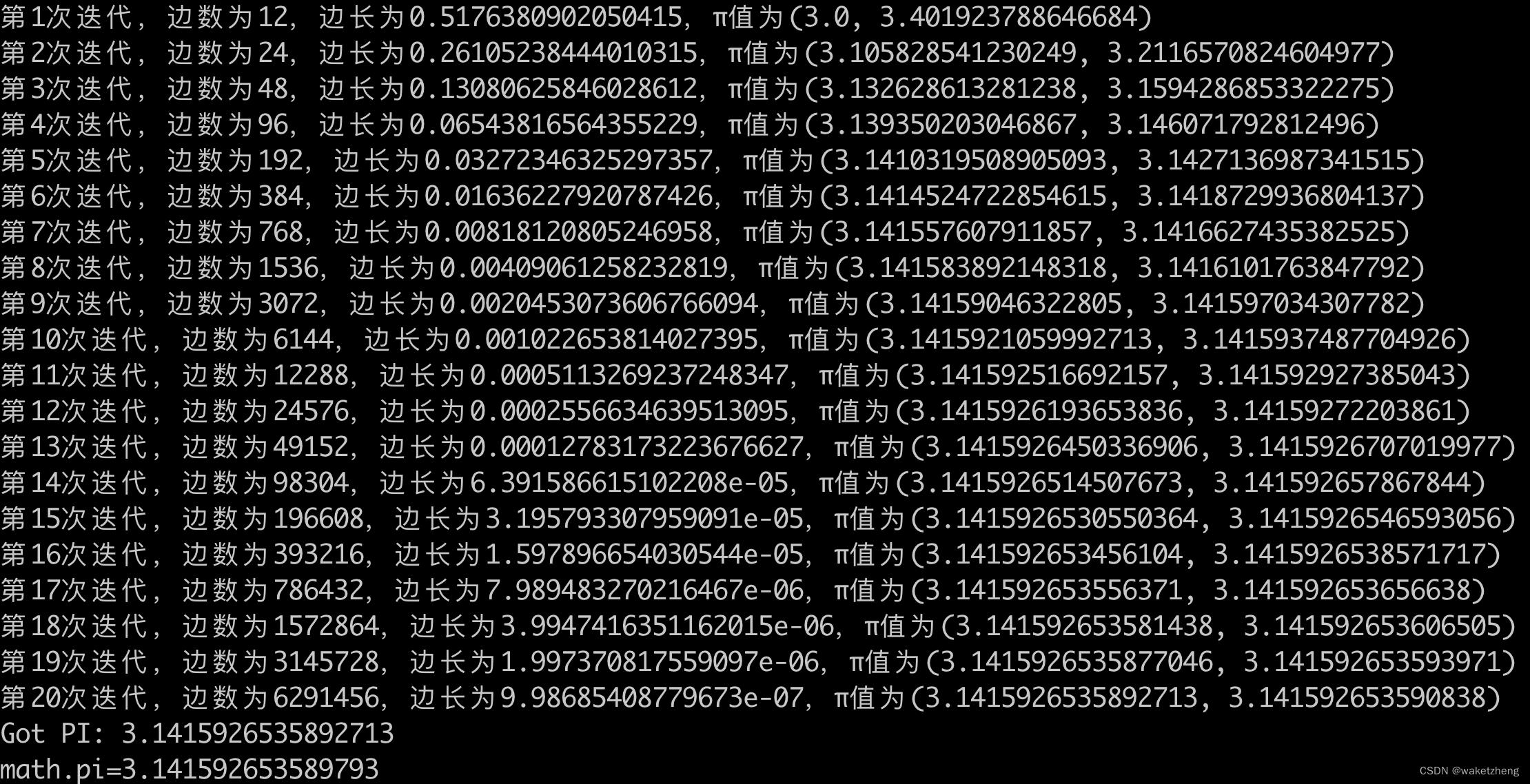
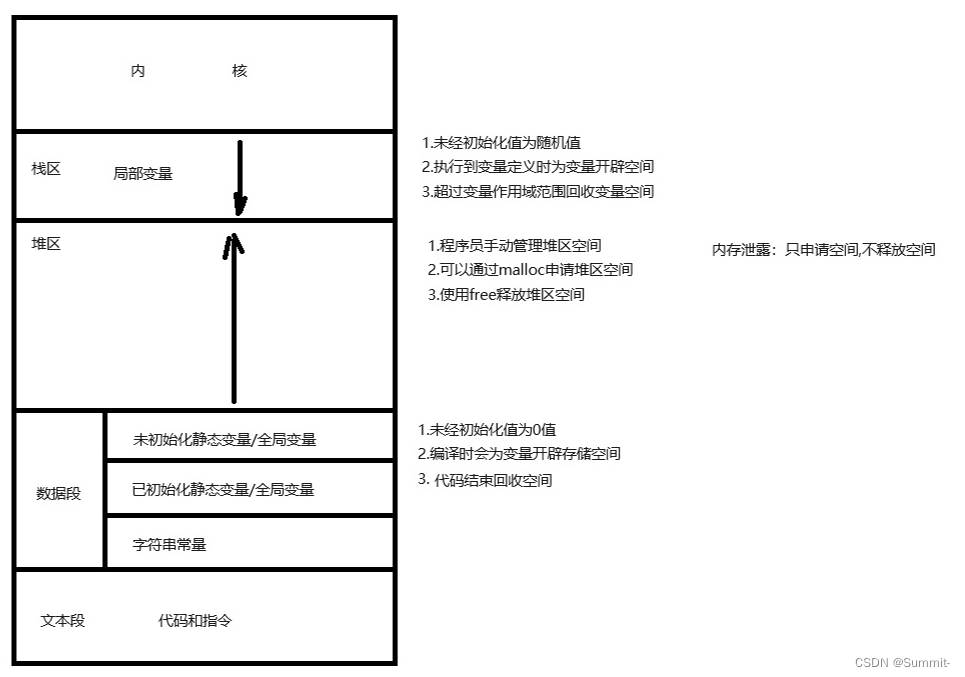
ncnn 算子操作描述,具体查询见
ncnn/docs/developer-guide/operators.md at master · Tencent/ncnn · GitHub
都是从上述地方copy过来的,做备份。
具体如下:
1.AbsVal: 计算输入张量中的每个元素的绝对值。
y = abs(x)
- one_blob_only 只支持一个blob
- support_inplace 支持替换输入的blob 就 y=abs(y)
import torch
input_tensor = torch.tensor([-1, 2, -3, 4, -5])
output_tensor = torch.abs(input_tensor)
print(output_tensor)
# tensor([1, 2, 3, 4, 5])
2.ArgMax: 计算输入张量中元素的最大值,并返回其位置索引。
y = argmax(x, out_max_val, topk)
- one_blob_only 支持一个blob
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | out_max_val | int | 0 | |
| 1 | topk | int | 1 |
import torch
input_tensor = torch.tensor([10, 5, 8, 20, 15])
output_index = torch.argmax(input_tensor)
print(output_index)
# tensor(3)3.BatchNorm: 对神经网络的每一层进行归一化操作。
y = (x - mean) / sqrt(var + eps) * slope + bias
- one_blob_only 支持一个参数
- support_inplace 支持替换
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | channels | int | 0 | |
| 1 | eps | float | 0.f |
| weight | type | shape |
|---|---|---|
| slope_data | float | [channels] |
| mean_data | float | [channels] |
| var_data | float | [channels] |
| bias_data | float | [channels] |
import torch
import torch.nn as nn
batch_norm_layer = nn.BatchNorm1d(3)
input_tensor = torch.randn(2, 3, 4) # Batch size为2,特征维度为3,序列长度为4
output_tensor = batch_norm_layer(input_tensor)
print(output_tensor)
# tensor([[[-0.5624, 0.9015, -0.9183, 0.3030],
# [ 0.4668, 1.0430, -2.0182, 0.7149],
# [-1.5960, 0.5437, 0.8771, -0.1269]],
#
# [[-0.1101, -1.4983, 1.9178, -0.0333],
# [-0.1873, -1.1687, 0.7301, 0.4194],
# [ 1.2667, 0.7976, -1.4188, -0.3434]]],
# grad_fn=<NativeBatchNormBackward0>)
4.Bias: 为神经网络的神经元或层添加偏置项。
y = x + bias
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | bias_data_size | int | 0 |
| weight | type | shape |
|---|---|---|
| bias_data | float | [channels] |
import torch
input_tensor = torch.randn(3, 4)
bias = torch.randn(4)
output_tensor = input_tensor + bias
print('output_tensor:',output_tensor,'\nshape:',output_tensor.shape)
# tensor([[-0.1874, 1.2358, 1.9006, 0.4483],
# [-1.1005, 1.6844, -0.3991, -0.4538],
# [ 0.4519, 2.2752, 1.6041, -1.2463]])
# shape: torch.Size([3, 4])5.BinaryOp: 二元操作
对两个输入执行特定的二元操作,如加法.减法等
This operation is used for binary computation, and the calculation rule depends on the broadcasting rule.(这个操作用于二进制计算,计算规则取决于广播规则。)
C = binaryop(A, B)
if with_scalar = 1:
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | op_type | int | 0 | Operation type as follows |
| 1 | with_scalar | int | 0 | with_scalar=0 B is a matrix, with_scalar=1 B is a scalar |
| 2 | b | float | 0.f | When B is a scalar, B = b |
Operation type:
- 0 = ADD(加法)
- 1 = SUB(减法)
- 2 = MUL(乘法)
- 3 = DIV(除法)
- 4 = MAX(取最大值)
- 5 = MIN(取最小值)
- 6 = POW(幂运算)
- 7 = RSUB(右操作数减去左操作数)
- 8 = RDIV(右操作数除以左操作数)
- 9 = RPOW(右操作数的左操作数次幂)
- 10 = ATAN2(反正切运算)
- 11 = RATAN2(右操作数以左操作数为底的反正切运算)
6.BNLL: 对输入应用 BNLL 激活函数
激活函数中的双极性 Sigmoid 函数
f(x)=log(1 + exp(x))
y = log(1 + e^(-x)) , x > 0
y = log(1 + e^x), x < 0
- one_blob_only
- support_inplace
7.Cast: 类型转换
将输入数据从一种数据类型转换为另一种数据类型
y = cast(x)
- one_blob_only
- support_packing
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | type_from | int | 0 | |
| 1 | type_to | int | 0 |
Element type:
- 0 = auto
- 1 = float32
- 2 = float16
- 3 = int8
- 4 = bfloat16
-
import torch input_tensor = torch.tensor([1.5, 2.3, 3.7]) output_tensor = input_tensor.type(torch.int) print(output_tensor) # tensor([1, 2, 3], dtype=torch.int32)
8.CELU: 应用 CELU 激活函数。
if x < 0 y = (exp(x / alpha) - 1.f) * alpha
else y = x
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | alpha | float | 1.f |
import torch
import torch.nn.functional as F
input_tensor = torch.randn(3, 4)
output_tensor = F.elu(input_tensor)
print('output_tensor:',output_tensor,'\nshape:',output_tensor.shape)
# output_tensor: tensor([[-0.5924, 0.7810, 1.1752, 0.8274],
# [-0.6871, 0.0466, 0.9411, -0.7082],
# [-0.8632, -0.1801, -0.8730, 0.9515]])
# shape: torch.Size([3, 4])
9.Clip: 将输入张量中的元素限制在指定范围内。
y = clamp(x, min, max)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | min | float | -FLT_MAX | |
| 1 | max | float | FLT_MAX |
import torch
input_tensor = torch.randn(2, 3)
output_tensor = torch.clamp(input_tensor, min=-0.5, max=0.5)
print(output_tensor)
# tensor([[-0.5000, -0.5000, -0.5000],
# [ 0.5000, -0.4091, -0.5000]])10.Concat: 沿指定轴连接多个输入张量。
y = concat(x0, x1, x2, ...) by axis
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | axis | int | 0 |
import torch
input_tensor1 = torch.randn(2, 3)
input_tensor2 = torch.randn(2, 3)
output_tensor = torch.cat((input_tensor1, input_tensor2), dim=1)
print('output_tensor:',output_tensor,'\nshape:',output_tensor.shape)
# output_tensor: tensor([[-2.4431, -0.6428, 0.4434, 1.2216, -1.1874, -1.1327],
# [-0.8082, -0.3552, 0.9945, -0.7679, 0.6547, -1.0401]])
# shape: torch.Size([2, 6])11.Convolution: 卷积操作
通过卷积操作提取输入数据的特征。
x2 = pad(x, pads, pad_value)
x3 = conv(x2, weight, kernel, stride, dilation) + bias
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 8 | int8_scale_term | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 18 | pad_value | float | 0.f | |
| 19 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [kernel_w, kernel_h, num_input, num_output] |
| bias_data | float | [num_output] |
| weight_data_int8_scales | float | [num_output] |
| bottom_blob_int8_scales | float | [1] |
| top_blob_int8_scales | float | [1] |
import torch
import torch.nn as nn
conv_layer = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
input_tensor = torch.randn(1, 3, 32, 32)
output_tensor = conv_layer(input_tensor)
print(output_tensor.shape)
# torch.Size([1, 16, 32, 32])12.Convolution1D:一维卷积
在一维数据上应用卷积操作。
x2 = pad(x, pads, pad_value)
x3 = conv1d(x2, weight, kernel, stride, dilation) + bias
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 15 | pad_right | int | pad_left | |
| 18 | pad_value | float | 0.f | |
| 19 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [kernel_w, num_input, num_output] |
| bias_data | float | [num_output] |
import torch
import torch.nn as nn
conv_layer = nn.Conv1d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
input_tensor = torch.randn(1, 3, 32)
output_tensor = conv_layer(input_tensor)
print(output_tensor.shape)
# torch.Size([1, 16, 32])13.Convolution3D:三维卷积
在三维数据上应用卷积操作。
x2 = pad(x, pads, pad_value)
x3 = conv3d(x2, weight, kernel, stride, dilation) + bias
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 17 | pad_behind | int | pad_front | |
| 18 | pad_value | float | 0.f | |
| 21 | kernel_d | int | kernel_w | |
| 22 | dilation_d | int | dilation_w | |
| 23 | stride_d | int | stride_w | |
| 24 | pad_front | int | pad_left |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [kernel_w, kernel_h, kernel_d, num_input, num_output] |
| bias_data | float | [num_output] |
import torch
import torch.nn as nn
conv_layer = nn.Conv3d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
input_tensor = torch.randn(1, 3, 32, 32, 32)
output_tensor = conv_layer(input_tensor)
print(output_tensor.shape)
# torch.Size([1, 16, 32, 32, 32])
14.ConvolutionDepthWise: 深度可分离卷积
对每个输入通道应用独立卷积核。
x2 = pad(x, pads, pad_value)
x3 = conv(x2, weight, kernel, stride, dilation, group) + bias
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 7 | group | int | 1 | |
| 8 | int8_scale_term | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 18 | pad_value | float | 0.f | |
| 19 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [kernel_w, kernel_h, num_input / group, num_output / group, group] |
| bias_data | float | [num_output] |
| weight_data_int8_scales | float | [group] |
| bottom_blob_int8_scales | float | [1] |
| top_blob_int8_scales | float | [1] |
import torch
import torch.nn as nn
conv_dw_layer = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, groups=3)
input_tensor = torch.randn(1, 3, 32, 32)
output_tensor = conv_dw_layer(input_tensor)
print(output_tensor.shape)
# torch.Size([1, 3, 30, 30])
15.ConvolutionDepthWise1D: 在一维数据上应用深度可分离卷积。
x2 = pad(x, pads, pad_value)
x3 = conv1d(x2, weight, kernel, stride, dilation, group) + bias
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 7 | group | int | 1 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 15 | pad_right | int | pad_left | |
| 18 | pad_value | float | 0.f | |
| 19 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [kernel_w, num_input / group, num_output / group, group] |
| bias_data | float | [num_output] |
import torch
import torch.nn as nn
# 定义一个一维的深度可分离卷积层
conv_dw_layer = nn.Conv1d(in_channels=3, out_channels=3, kernel_size=3, groups=3)
# 创建一个随机输入张量
input_tensor = torch.randn(1, 3, 10) # 输入张量的形状为 (batch_size, channels, sequence_length)
# 将输入张量传递给深度可分离卷积层
output_tensor = conv_dw_layer(input_tensor)
print(output_tensor.shape)
# torch.Size([1, 3, 8])
16.ConvolutionDepthWise3D: 在三维数据上应用深度可分离卷积。
x2 = pad(x, pads, pad_value)
x3 = conv1d(x2, weight, kernel, stride, dilation, group) + bias
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 7 | group | int | 1 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 15 | pad_right | int | pad_left | |
| 18 | pad_value | float | 0.f | |
| 19 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [kernel_w, num_input / group, num_output / group, group] |
| bias_data | float | [num_output] |
17.CopyTo: 将输入数据复制到指定位置
self[offset] = src
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | woffset | int | 0 | |
| 1 | hoffset | int | 0 | |
| 13 | doffset | int | 0 | |
| 2 | coffset | int | 0 | |
| 9 | starts | array | [ ] | |
| 11 | axes | array | [ ] |
18.Crop: 裁剪操作
对输入数据进行裁剪操作,保留感兴趣的部分。
y = crop(x)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | woffset | int | 0 | |
| 1 | hoffset | int | 0 | |
| 13 | doffset | int | 0 | |
| 2 | coffset | int | 0 | |
| 3 | outw | int | 0 | |
| 4 | outh | int | 0 | |
| 14 | outd | int | 0 | |
| 5 | outc | int | 0 | |
| 6 | woffset2 | int | 0 | |
| 7 | hoffset2 | int | 0 | |
| 15 | doffset2 | int | 0 | |
| 8 | coffset2 | int | 0 | |
| 9 | starts | array | [ ] | |
| 10 | ends | array | [ ] | |
| 11 | axes | array | [ ] |
import torch
# 创建一个3x3的张量
tensor = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 进行裁剪,选取其中部分区域
cropped_tensor = tensor[1:, 1:]
print(cropped_tensor)
# tensor([[5, 6],
# [8, 9]])19.CumulativeSum: 对输入数据进行累积求和操作。
If axis < 0, we use axis = x.dims + axis
It implements torch.cumsum — PyTorch 2.3 documentation
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | axis | int | 0 |
20.Deconvolution: 反卷积操作
用于图像生成和语义分割任务等。
x2 = deconv(x, weight, kernel, stride, dilation) + bias
x3 = depad(x2, pads, pad_value)
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 18 | output_pad_right | int | 0 | |
| 19 | output_pad_bottom | int | output_pad_right | |
| 20 | output_w | int | 0 | |
| 21 | output_h | int | output_w | |
| 28 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16 | [kernel_w, kernel_h, num_input, num_output] |
| bias_data | float | [num_output] |
21.Deconvolution1D: 一维反卷积操作
在一维数据上应用反卷积操作。
x2 = deconv1d(x, weight, kernel, stride, dilation) + bias
x3 = depad(x2, pads, pad_value)
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 15 | pad_right | int | pad_left | |
| 18 | output_pad_right | int | 0 | |
| 20 | output_w | int | 0 | |
| 28 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16 | [kernel_w, num_input, num_output] |
| bias_data | float | [num_output] |
22.Deconvolution3D: 三维反卷积操作
在三维数据上应用反卷积操作。
x2 = deconv3d(x, weight, kernel, stride, dilation) + bias
x3 = depad(x2, pads, pad_value)
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 17 | pad_behind | int | pad_front | |
| 18 | output_pad_right | int | 0 | |
| 19 | output_pad_bottom | int | output_pad_right | |
| 20 | output_pad_behind | int | output_pad_right | |
| 21 | kernel_d | int | kernel_w | |
| 22 | dilation_d | int | dilation_w | |
| 23 | stride_d | int | stride_w | |
| 24 | pad_front | int | pad_left | |
| 25 | output_w | int | 0 | |
| 26 | output_h | int | output_w | |
| 27 | output_d | int | output_w |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16 | [kernel_w, kernel_h, kernel_d, num_input, num_output] |
| bias_data | float | [num_output] |
23.DeconvolutionDepthWise: 深度可分离反卷积。
x2 = deconv(x, weight, kernel, stride, dilation, group) + bias
x3 = depad(x2, pads, pad_value)
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 7 | group | int | 1 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 18 | output_pad_right | int | 0 | |
| 19 | output_pad_bottom | int | output_pad_right | |
| 20 | output_w | int | 0 | |
| 21 | output_h | int | output_w | |
| 28 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16 | [kernel_w, kernel_h, num_input / group, num_output / group, group] |
| bias_data | float | [num_output] |
24.DeconvolutionDepthWise1D: 在一维数据上应用深度可分离反卷积。
x2 = deconv1d(x, weight, kernel, stride, dilation, group) + bias
x3 = depad(x2, pads, pad_value)
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 7 | group | int | 1 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 15 | pad_right | int | pad_left | |
| 18 | output_pad_right | int | 0 | |
| 20 | output_w | int | 0 | |
| 28 | dynamic_weight | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16 | [kernel_w, num_input / group, num_output / group, group] |
| bias_data | float | [num_output] |
25.DeconvolutionDepthWise3D: 三维深度可分离反卷积
在三维数据上应用深度可分离反卷积。
x2 = deconv3d(x, weight, kernel, stride, dilation, group) + bias
x3 = depad(x2, pads, pad_value)
y = activation(x3, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 7 | group | int | 1 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 17 | pad_behind | int | pad_front | |
| 18 | output_pad_right | int | 0 | |
| 19 | output_pad_bottom | int | output_pad_right | |
| 20 | output_pad_behind | int | output_pad_right | |
| 21 | kernel_d | int | kernel_w | |
| 22 | dilation_d | int | dilation_w | |
| 23 | stride_d | int | stride_w | |
| 24 | pad_front | int | pad_left | |
| 25 | output_w | int | 0 | |
| 26 | output_h | int | output_w | |
| 27 | output_d | int | output_w |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16 | [kernel_w, kernel_h, kernel_d, num_input / group, num_output / group, group] |
| bias_data | float | [num_output] |
26.DeformableConv2D: 可变形卷积,允许卷积核在空间上变形。
x2 = deformableconv2d(x, offset, mask, weight, kernel, stride, dilation) + bias
y = activation(x2, act_type, act_params)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 5 | bias_term | int | 0 | |
| 6 | weight_data_size | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [kernel_w, kernel_h, num_input, num_output] |
| bias_data | float | [num_output] |
27.Dequantize: 对量化后的数据进行反量化操作。
将量化后的数据还原为原始浮点数形式的过程,通常用于将量化后的激活值或权重恢复为浮点数,以便进行后续的计算
y = x * scale + bias
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | scale_data_size | int | 1 | |
| 1 | bias_data_size | int | 0 |
| weight | type | shape |
|---|---|---|
| scale_data | float | [scale_data_size] |
| bias_data | float | [bias_data_size] |
#对激活值(Activation)进行Dequantization:
import torch
# 假设quantized_tensor为量化后的张量
quantized_tensor = torch.tensor([0, 1, 2, 3], dtype=torch.uint8) # 假设使用8位无符号整数进行量化
# 进行Dequantization
dequantized_tensor = quantized_tensor.float() # 将数据类型转换为float类型,即将量化后的整数数据转换为浮点数
print(dequantized_tensor)
# tensor([0., 1., 2., 3.])#对权重(Weights)进行Dequantization
import torch
# 假设quantized_weights为量化后的权重张量
quantized_weights = torch.tensor([-1, 0, 1, 2], dtype=torch.int8) # 假设使用8位有符号整数进行量化
# 进行Dequantization
scale = 0.01 # 量化比例
dequantized_weights = quantized_weights.float() * scale # 将量化后的整数数据乘以比例因子以完成反量化操作
print(dequantized_weights)
# tensor([-0.0100, 0.0000, 0.0100, 0.0200])28.Diag: 创建一个对角阵。
对角矩阵是一个主对角线以外的所有元素均为零的矩阵,而主对角线上的元素可以为零或非零。
如下:

y = diag(x, diagonal)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | diagonal | int | 0 |
import torch
# 创建一个包含对角线元素为 [1, 2, 3] 的对角矩阵
diagonal_elements = torch.tensor([1, 2, 3])
diagonal_matrix = torch.diag(diagonal_elements)
print(diagonal_matrix)
# tensor([[1, 0, 0],
# [0, 2, 0],
# [0, 0, 3]])29.Dropout: 随机失活
在训练过程中随机断开神经元连接,用于防止过拟合。
y = x * scale
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | scale | float | 1.f |
import torch
import torch.nn as nn
# 创建一个包含两个全连接层和一个Dropout层的神经网络
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(10, 5)
self.dropout = nn.Dropout(p=0.5) # 创建一个保留概率为0.5的Dropout层
self.fc2 = nn.Linear(5, 2)
def forward(self, x):
x = self.fc1(x)
x = self.dropout(x) # 在全连接层1的输出上应用Dropout
x = torch.relu(x)
x = self.fc2(x)
return x
# 创建模型实例
model = MyModel()
# 在训练时,使用model.train()来开启Dropout
model.train()
# 输入数据示例
input_data = torch.randn(1, 10) # 创建一个大小为(1, 10)的张量
# 前向传播
output = model(input_data)
print(output)
# tensor([[0.7759, 0.4466]], grad_fn=<AddmmBackward0>)
30.Eltwise: 逐元素操作
对输入执行元素级操作,如加法.乘法等。
y = elementwise_op(x0, x1, ...)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | op_type | int | 0 | |
| 1 | coeffs | array | [ ] |
Operation type:
- 0 = PROD
- 1 = SUM
- 2 = MAX
-
import torch # 创建两个张量 a = torch.tensor([1, 2, 3]) b = torch.tensor([4, 5, 6]) # 0 = PROD,逐元素相乘 prod_result = torch.mul(a, b) print("Elementwise product result:", prod_result) # Elementwise product result: tensor([ 4, 10, 18]) # 1 = SUM,逐元素相加 sum_result = torch.add(a, b) print("Elementwise sum result:", sum_result) # Elementwise sum result: tensor([5, 7, 9]) # 2 = MAX,逐元素取最大值 max_result = torch.maximum(a, b) print("Elementwise max result:", max_result) # Elementwise max result: tensor([4, 5, 6])
31.ELU: 应用指数线性单元(ELU)激活函数。
if x < 0 y = (exp(x) - 1) * alpha
else y = x
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | alpha | float | 0.1f |
32.Embed: 将输入数据映射到低维空间。
词向量啊,万物皆可embed
将高维稀疏的数据编码成低维稠密向量表示的技术,通常用于将离散的类别型数据(例如单词、产品ID等)映射到连续的实数向量空间中
y = embedding(x)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | input_dim | int | 0 | |
| 2 | bias_term | int | 0 | |
| 3 | weight_data_size | int | 0 |
| weight | type | shape |
|---|---|---|
| weight_data | float | [weight_data_size] |
| bias_term | float | [num_output] |
import torch
import torch.nn as nn
# 假设我们有10个不同的词,需要将它们映射成一个5维的稠密向量
vocab_size = 10
embedding_dim = 5
# 创建一个Embedding层
embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim)
# 定义一个输入,假设我们要获取ID为3和7的词的向量表示
input_ids = torch.LongTensor([3, 7])
# 通过Embedding层获取对应词的向量表示
output = embedding(input_ids)
print(output)
# tensor([[-0.4583, 2.2385, 1.1503, 0.4575, -0.5081],
# [ 2.1852, -1.2893, 0.6631, 0.1552, 1.6735]],
# grad_fn=<EmbeddingBackward0>)33.Exp: 计算输入数据的指数。
if base == -1 y = exp(shift + x * scale)
else y = pow(base, (shift + x * scale))
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | base | float | -1.f | |
| 1 | scale | float | 1.f | |
| 2 | shift | float | 0.f |
34.Flatten: 将输入数据展平为一维。
Reshape blob to 1 dimension(将其重塑为一维数组。)
- one_blob_only
-
import torch # 创建一个3维张量,例如(2, 3, 4),表示(batch_size, channels, height, width) input_tensor = torch.randn(2, 3, 4) # 使用torch.flatten()将张量展平 output_tensor1 = torch.flatten(input_tensor, start_dim=0) # 使用torch.flatten()将张量展平 output_tensor2 = input_tensor.view(2*3*4) print("Input Tensor shape:", input_tensor.shape) print("Flattened Tensor shape:", output_tensor1.shape) print("view Tensor shape:", output_tensor2.shape) # Input Tensor shape: torch.Size([2, 3, 4]) # Flattened Tensor shape: torch.Size([24]) # view Tensor shape: torch.Size([24])
35.Fold: 折叠操作
对输入数据进行折叠操作,与展平相反。
y = fold(x)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top | |
| 20 | output_w | int | 0 | |
| 21 | output_h | int | output_w |
import torch
# 创建一个4x4的张量
x = torch.arange(1, 17).view(4, 4)
print("Original tensor:")
print(x)
# Original tensor:
# tensor([[ 1, 2, 3, 4],
# [ 5, 6, 7, 8],
# [ 9, 10, 11, 12],
# [13, 14, 15, 16]])
# 对张量进行fold操作 4x4 =16 分成 2x8 或者8x2 、1x16 、2x2x2x2其他 等等
folded_tensor = x.view(2,2,2,2)
print("Folded tensor:")
print(folded_tensor)
# Folded tensor:
# tensor([[[[ 1, 2],
# [ 3, 4]],
#
# [[ 5, 6],
# [ 7, 8]]],
#
#
# [[[ 9, 10],
# [11, 12]],
#
# [[13, 14],
# [15, 16]]]])36.GELU: 应用高斯误差线性单元(GELU)激活函数。
if fast_gelu == 1 y = 0.5 * x * (1 + tanh(0.79788452 * (x + 0.044715 * x * x * x)));
else y = 0.5 * x * erfc(-0.70710678 * x)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | fast_gelu | int | 0 | use approximation |
37.GLU: 应用门控线性单元(GLU)激活函数。
If axis < 0, we use axis = x.dims + axis
GLU(a,b)=a⊗σ(b)
where a is the first half of the input matrix and b is the second half.
axis specifies the dimension to split the input
a 是输入矩阵的前一半,b 是后一半。
axis 参数用于指定沿着哪个维度(dimension)对输入矩阵进行分割。
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | axis | int | 0 |
38.Gemm: 执行矩阵乘法操作。
a = transA ? transpose(x0) : x0
b = transb ? transpose(x1) : x1
c = x2
y = (gemm(a, b) + c * beta) * alpha
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | alpha | float | 1.f | |
| 1 | beta | float | 1.f | |
| 2 | transA | int | 0 | |
| 3 | transb | int | 0 | |
| 4 | constantA | int | 0 | |
| 5 | constantB | int | 0 | |
| 6 | constantC | int | 0 | |
| 7 | constantM | int | 0 | |
| 8 | constantN | int | 0 | |
| 9 | constantK | int | 0 | |
| 10 | constant_broadcast_type_C | int | 0 | |
| 11 | output_N1M | int | 0 | |
| 12 | output_elempack | int | 0 | |
| 13 | output_elemtype | int | 0 | |
| 14 | output_transpose | int | 0 | |
| 20 | constant_TILE_M | int | 0 | |
| 21 | constant_TILE_N | int | 0 | |
| 22 | constant_TILE_K | int | 0 |
| weight | type | shape |
|---|---|---|
| A_data | float | [M, K] or [K, M] |
| B_data | float | [N, K] or [K, N] |
| C_data | float | [1], [M] or [N] or [1, M] or [N,1] or [N, M] |
import torch
# 创建两个矩阵
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6], [7, 8]])
# 执行矩阵乘法
C = torch.matmul(A, B)
print("Matrix A:")
print(A)
print("Matrix B:")
print(B)
print("Result of Matrix Multiplication:")
print(C)
# Matrix A:
# tensor([[1, 2],
# [3, 4]])
# Matrix B:
# tensor([[5, 6],
# [7, 8]])
# Result of Matrix Multiplication:
# tensor([[19, 22],
# [43, 50]])39.GridSample: 在输入的网格上进行采样操作。
根据输入的采样网格(sampling grid)中指定的坐标,在输入张量上进行采样,输出对应的插值结果
Given an input and a flow-field grid, computes the output using input values and pixel locations from grid.
For each output location output[:, h2, w2], the size-2 vector grid[h2, w2, 2] specifies input pixel[:, h1, w1] locations x and y,
which are used to interpolate the output value output[:, h2, w2]
This function is often used in conjunction with affine_grid() to build Spatial Transformer Networks .
给定一个输入和一个flow-field流场网格,使用输入值和来自网格的像素位置,计算输出。
对于每个输出位置 output[:, h2, w2],大小为2的向量 grid[h2, w2, 2] 指定了输入像素[:, h1, w1] 的位置 x 和 y,用于进行输出值 output[:, h2, w2] 的插值计算。
这个函数通常与 affine_grid() 一起使用,用于构建空间变换网络(Spatial Transformer Networks)。
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | sample_type | int | 1 | |
| 1 | padding_mode | int | 1 | |
| 2 | align_corner | int | 0 | |
| 3 | permute_fusion | int | 0 | fuse with permute |
Sample type:
- 1 = Nearest
- 2 = Bilinear
- 3 = Bicubic
Padding mode:
- 1 = zeros
- 2 = border
- 3 = reflection
-
#引用 https://www.cnblogs.com/yanghailin/p/17747266.html import torch from torch.nn import functional as F inp = torch.randint(10, 20, (1, 1, 20, 20)).float() print('inp.shape:', inp.shape) # 得到一个长宽为20的tensor out_h = 40 out_w = 40 # 生成grid点 grid_h = torch.linspace(-1, 1, out_h).view(1, -1, 1).expand(1, out_h, out_w) grid_w = torch.linspace(-1, 1, out_w).view(1, 1, -1).expand(1, out_h, out_w) grid = torch.stack((grid_h, grid_w), dim=3) # grid的形状为 [1, 20, 20, 2] outp = F.grid_sample(inp, grid=grid, mode='bilinear') print(outp.shape) # torch.Size([1, 1, 20, 20]) print("Input tensor:") print(inp) print("Output tensor after grid sampling:") print(outp) # inp.shape: torch.Size([1, 1, 20, 20]) # torch.Size([1, 1, 40, 40]) # Input tensor: # tensor([[[[16., 17., 16., 10., 16., 11., 13., 17., 16., 15., 10., 10., 13., 17., # 11., 19., 12., 11., 10., 12.], # [12., 15., 17., 16., 13., 13., 16., 19., 18., 10., 11., 13., 19., 14., # 14., 18., 14., 11., 10., 15.], # [12., 11., 18., 10., 15., 15., 17., 10., 10., 14., 18., 15., 12., 16., # 10., 18., 16., 16., 10., 16.], # [17., 17., 12., 11., 16., 16., 10., 16., 17., 16., 13., 10., 18., 18., # 17., 17., 17., 10., 16., 19.], # [14., 15., 16., 19., 12., 12., 11., 10., 16., 12., 16., 10., 17., 10., # 12., 18., 19., 13., 13., 16.], # [15., 19., 17., 18., 15., 16., 15., 10., 19., 15., 11., 16., 18., 14., # 19., 10., 13., 16., 18., 19.], # [13., 13., 14., 11., 15., 13., 18., 14., 10., 13., 13., 11., 17., 13., # 17., 13., 10., 12., 14., 10.], # [12., 10., 17., 16., 17., 10., 18., 15., 14., 13., 13., 10., 17., 16., # 19., 13., 14., 10., 17., 12.], # [12., 14., 18., 15., 16., 14., 13., 14., 13., 13., 17., 11., 15., 18., # 19., 14., 12., 14., 12., 14.], # [12., 13., 17., 14., 18., 16., 14., 16., 14., 15., 19., 13., 19., 17., # 12., 18., 15., 12., 16., 11.], # [10., 19., 12., 13., 12., 17., 14., 13., 19., 19., 12., 13., 17., 17., # 14., 17., 11., 14., 18., 12.], # [10., 19., 19., 11., 16., 16., 15., 17., 10., 13., 16., 10., 17., 10., # 15., 11., 11., 17., 15., 17.], # [13., 12., 10., 11., 11., 16., 16., 16., 10., 10., 13., 19., 14., 13., # 18., 15., 12., 19., 14., 16.], # [16., 13., 11., 11., 12., 16., 12., 16., 10., 16., 11., 19., 19., 12., # 11., 15., 11., 15., 12., 17.], # [17., 12., 17., 10., 15., 12., 13., 16., 14., 15., 19., 17., 17., 12., # 10., 18., 19., 12., 15., 13.], # [10., 15., 16., 10., 13., 19., 17., 19., 18., 18., 12., 14., 13., 12., # 18., 17., 12., 17., 14., 17.], # [13., 10., 15., 19., 19., 14., 11., 14., 11., 13., 19., 10., 10., 13., # 16., 11., 15., 13., 18., 15.], # [19., 10., 15., 15., 13., 13., 15., 13., 15., 18., 13., 10., 14., 10., # 13., 14., 16., 12., 17., 12.], # [12., 10., 17., 15., 19., 12., 19., 11., 14., 19., 16., 11., 17., 14., # 15., 12., 12., 14., 18., 15.], # [12., 15., 14., 18., 19., 19., 17., 11., 11., 12., 13., 19., 17., 19., # 10., 17., 15., 18., 14., 10.]]]]) # Output tensor after grid sampling: # tensor([[[[ 4.0000, 7.9744, 6.9487, ..., 6.0000, 6.0000, 3.0000], # [ 8.0064, 15.9619, 13.9237, ..., 12.0048, 12.0376, 6.0192], # [ 8.2628, 16.4878, 14.9757, ..., 12.1954, 13.5432, 6.7885], # ..., # [ 5.4744, 10.9670, 11.6967, ..., 14.4545, 12.1599, 6.0513], # [ 5.9872, 12.0123, 13.5311, ..., 12.6727, 10.1152, 5.0256], # [ 3.0000, 6.0192, 6.7885, ..., 6.3141, 5.0321, 2.5000]]]])
40.GroupNorm: 对神经网络中的特征图执行分组归一化。
将特征通道分为多个组,每个组包含一定数量的通道,然后对每个组内的通道进行独立的规范化操作。
split x along channel axis into group x0, x1 ...
l2 normalize for each group x0, x1 ...
y = x * gamma + beta
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | group | int | 1 | |
| 1 | channels | int | 0 | |
| 2 | eps | float | 0.001f | x = x / sqrt(var + eps) |
| 3 | affine | int | 1 |
| weight | type | shape |
|---|---|---|
| gamma_data | float | [channels] |
| beta_data | float | [channels] |
import torch
import torch.nn as nn
# 定义一个输入张量
input_tensor = torch.randn(1, 6, 4, 4) # (batch_size, num_channels, height, width)
# 使用GroupNorm,假设分成2组
num_groups = 2
group_norm = nn.GroupNorm(num_groups, 6) # num_groups为组数,6为输入通道数
# 对输入张量进行GroupNorm操作
output = group_norm(input_tensor)
# 打印输入输出形状
print("Input shape:", input_tensor.shape)
print("Output shape after GroupNorm:", output.shape)
# Input shape: torch.Size([1, 6, 4, 4])
# Output shape after GroupNorm: torch.Size([1, 6, 4, 4])41.GRU: 门控循环单元(GRU)神经网络层。
是一种常用的递归神经网络(RNN)变体,用于处理序列数据。与标准RNN相比,GRU引入了门控机制,有助于更好地捕捉长期依赖关系
Apply a single-layer GRU to a feature sequence of T timesteps. The input blob shape is [w=input_size, h=T] and the output blob shape is [w=num_output, h=T].
y = gru(x)
y0, hidden y1 = gru(x0, hidden x1)
- one_blob_only if bidirectional
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | hidden size of output |
| 1 | weight_data_size | int | 0 | total size of weight matrix |
| 2 | direction | int | 0 | 0=forward, 1=reverse, 2=bidirectional |
| weight | type | shape |
|---|---|---|
| weight_xc_data | float/fp16/int8 | [input_size, num_output * 3, num_directions] |
| bias_c_data | float/fp16/int8 | [num_output, 4, num_directions] |
| weight_hc_data | float/fp16/int8 | [num_output, num_output * 3, num_directions] |
Direction flag:
- 0 = forward only
- 1 = reverse only
- 2 = bidirectional
-
import torch import torch.nn as nn # 假设输入维度为3,隐藏单元数为4 input_size = 3 hidden_size = 4 # 定义一个GRU层 gru = nn.GRU(input_size, hidden_size) # 默认情况下,没有指定层数,默认为单层 # 定义一个输入序列,假设序列长度为2,批量大小为1 input_seq = torch.randn(2, 1, 3) # (seq_len, batch_size, input_size) # 初始化隐藏状态 hidden = torch.zeros(1, 1, 4) # (num_layers, batch_size, hidden_size) # 将输入序列传递给GRU层 output, hidden = gru(input_seq, hidden) # 打印输出和隐藏状态的形状 print("Output shape:", output.shape) # (seq_len, batch_size, num_directions * hidden_size) print("Hidden state shape:", hidden.shape) # (num_layers * num_directions, batch, hidden_size) # Output shape: torch.Size([2, 1, 4]) # Hidden state shape: torch.Size([1, 1, 4])
42.HardSigmoid: 应用硬Sigmoid激活函数。
在神经网络中通常用于限制神经元的激活范围。与标准的 Sigmoid 函数相比,HardSigmoid 是一种更简单和高效的近似函数,通常用于加速模型的训练过程
y = clamp(x * alpha + beta, 0, 1)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | alpha | float | 0.2f | |
| 1 | beta | float | 0.5f |
import torch
import torch.nn.functional as F
# 定义输入张量
input_tensor = torch.randn(3, 4) # 假设输入张量大小为3x4
# 使用HardSigmoid激活函数
output = F.hardsigmoid(input_tensor) # HardSigmoid(x) = clip(0.2*x + 0.5, 0, 1)
# 打印输入和输出张量
print("Input tensor:")
print(input_tensor)
# Input tensor:
# tensor([[ 0.5026, 0.6612, -0.0961, 1.9332],
# [-0.8780, -0.4930, -0.2804, -0.0440],
# [ 1.2866, -1.9575, 0.7738, -0.8340]])
print("\nOutput tensor after HardSigmoid:")
print(output)
# Output tensor after HardSigmoid:
# tensor([[0.5838, 0.6102, 0.4840, 0.8222],
# [0.3537, 0.4178, 0.4533, 0.4927],
# [0.7144, 0.1738, 0.6290, 0.3610]])43.HardSwish: 应用硬Swish激活函数。
y = x * clamp(x * alpha + beta, 0, 1)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | alpha | float | 0.2f | |
| 1 | beta | float | 0.5f |
import torch
import torch.nn.functional as F
# 定义 HardSwish 激活函数
def hardswish(x):
return x * F.hardsigmoid(x + 3, inplace=True)
# 创建一个张量作为输入
input_tensor = torch.randn(3, 4) # 假设输入张量大小为 3x4
# 应用 HardSwish 激活函数
output = hardswish(input_tensor)
# 打印输入张量和输出张量
print("Input tensor:")
print(input_tensor)
print("\nOutput tensor after HardSwish:")
print(output)
# Input tensor:
# tensor([[ 0.4330, -1.9232, 1.9127, 0.6024],
# [-0.2073, 0.1116, -0.6153, 0.5362],
# [-1.4893, 0.0764, -0.1484, -0.0945]])
#
# Output tensor after HardSwish:
# tensor([[ 0.4330, -1.3068, 1.9127, 0.6024],
# [-0.2001, 0.1116, -0.5522, 0.5362],
# [-1.1197, 0.0764, -0.1447, -0.0930]])44.InnerProduct: 执行全连接操作。
将输入的所有特征连接到输出层的每个神经元,实现了每个神经元与前一层的所有神经元之间的连接
x2 = innerproduct(x, weight) + bias
y = activation(x2, act_type, act_params)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | bias_term | int | 0 | |
| 2 | weight_data_size | int | 0 | |
| 8 | int8_scale_term | int | 0 | |
| 9 | activation_type | int | 0 | |
| 10 | activation_params | array | [ ] |
| weight | type | shape |
|---|---|---|
| weight_data | float/fp16/int8 | [num_input, num_output] |
| bias_data | float | [num_output] |
| weight_data_int8_scales | float | [num_output] |
| bottom_blob_int8_scales | float | [1] |
import torch
import torch.nn as nn
class InnerProduct(nn.Module):
def __init__(self, in_features, out_features):
super(InnerProduct, self).__init__()
self.fc = nn.Linear(in_features, out_features)
def forward(self, x):
return self.fc(x)
# 创建一个 InnerProduct 层
inner_product_layer = InnerProduct(100, 200) # 假设输入特征维度为 100,输出特征维度为 200
# 定义输入数据
input_data = torch.randn(1, 100) # 假设输入数据为 1 组,每组包含 100 个特征
# 运行 InnerProduct 层
output = inner_product_layer(input_data)
print(output.shape) # 输出特征的形状
# torch.Size([1, 200])45.Input: 神经网络的输入层
y = input
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | w | int | 0 | |
| 1 | h | int | 0 | |
| 11 | d | int | 0 | |
| 2 | c | int | 0 |
46.InstanceNorm: 归一化操作
一种归一化技术,通常用于神经网络中的层级操作。实例归一化独立地标准化每个样本的特征,而不是整个批次的特征。这种归一化方式可以帮助模型更好地学习特征表示,提高收敛速度并加速训练
split x along channel axis into instance x0, x1 ...
l2 normalize for each channel instance x0, x1 ...
y = x * gamma + beta
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | channels | int | 0 | |
| 1 | eps | float | 0.001f | x = x / sqrt(var + eps) |
| 2 | affine | int | 1 |
| weight | type | shape |
|---|---|---|
| gamma_data | float | [channels] |
| beta_data | float | [channels] |
import torch
import torch.nn as nn
# 创建一个实例归一化层
instance_norm_layer = nn.InstanceNorm2d(3) # 通道数为 3
# 随机生成一组特征图作为输入数据
input_data = torch.randn(1, 3, 224, 224) # 假设输入数据为 1 组,通道数为 3,图像尺寸为 224x224
# 运行实例归一化层
output = instance_norm_layer(input_data)
print(output.shape) # 输出特征的形状
# torch.Size([1, 3, 224, 224])47.Interp: 执行插值操作
在计算机视觉领域,插值通常用于调整图像的大小,从而实现图像的放大、缩小或者调整分辨率等操作
if dynamic_target_size == 0 y = resize(x) by fixed size or scale
else y = resize(x0, size(x1))
- one_blob_only if dynamic_target_size == 0
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | resize_type | int | 0 | |
| 1 | height_scale | float | 1.f | |
| 2 | width_scale | float | 1.f | |
| 3 | output_height | int | 0 | |
| 4 | output_width | int | 0 | |
| 5 | dynamic_target_size | int | 0 | |
| 6 | align_corner | int | 0 |
Resize type:
- 1 = Nearest
- 2 = Bilinear
- 3 = Bicubic
-
import torch import torch.nn.functional as F # 创建一个随机的特征图作为输入数据 input_data = torch.randn(1, 3, 224, 224) # 假设输入数据为 1 组,通道数为 3,图像尺寸为 224x224 # 执行双线性插值将图像大小调整到 300x300 output = F.interpolate(input_data, size=(300, 300), mode='bilinear', align_corners=False) print(output.shape) # 输出特征的形状 # torch.Size([1, 3, 300, 300])
48.LayerNorm: 对神经网络中的层执行归一化操作
是一种用于神经网络中的归一化技术,与 Batch Normalization 不同,Layer Normalization 是对单个样本的特征进行标准化,而不是对整个批次。层归一化有助于减少内部协变量偏移,从而加速网络训练过程并提高泛化性能
split x along outmost axis into part x0, x1 ...
l2 normalize for each part x0, x1 ...
y = x * gamma + beta by elementwise
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | affine_size | int | 0 | |
| 1 | eps | float | 0.001f | x = x / sqrt(var + eps) |
| 2 | affine | int | 1 |
| weight | type | shape |
|---|---|---|
| gamma_data | float | [affine_size] |
| beta_data | float | [affine_size] |
import torch
import torch.nn as nn
# 创建一个层归一化模块
layer_norm = nn.LayerNorm(256) # 输入特征的尺寸为 256
# 随机生成一组特征作为输入数据
input_data = torch.randn(4, 256) # 假设输入数据为 4 组,每组特征的尺寸为 256
# 运行层归一化模块
output = layer_norm(input_data)
print(output.shape) # 输出特征的形状
# torch.Size([4, 256])49.Log: 计算输入数据的自然对数。
if base == -1 y = log(shift + x * scale)
else y = log(shift + x * scale) / log(base)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | base | float | -1.f | |
| 1 | scale | float | 1.f | |
| 2 | shift | float | 0.f |
50.LRN: 局部响应归一化层。
一种局部归一化的方法,用于一些深度学习模型中,旨在模拟生物神经元系统中的侧抑制机制。LRN 主要用于提升模型的泛化能力,防止模型过拟合
if region_type == ACROSS_CHANNELS square_sum = sum of channel window of local_size
if region_type == WITHIN_CHANNEL square_sum = sum of spatial window of local_size
y = x * pow(bias + alpha * square_sum / (local_size * local_size), -beta)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | region_type | int | 0 | |
| 1 | local_size | int | 5 | |
| 2 | alpha | float | 1.f | |
| 3 | beta | float | 0.75f | |
| 4 | bias | float | 1.f |
Region type:
- 0 = ACROSS_CHANNELS
- 1 = WITHIN_CHANNEL
-
import torch import torch.nn as nn class LRN(nn.Module): def __init__(self, size=5, alpha=1e-4, beta=0.75, k=1.0): super(LRN, self).__init__() self.size = size self.alpha = alpha self.beta = beta self.k = k def forward(self, x): squared = x.pow(2) pool = nn.functional.avg_pool2d(squared, self.size, stride=1, padding=self.size//2) denom = self.k + self.alpha * pool output = x / denom.pow(self.beta) return output # 创建一个 LRN 模块实例 lrn = LRN(size=3, alpha=1e-4, beta=0.75, k=1.0) # 随机生成一组特征作为输入数据 input_data = torch.randn(1, 3, 224, 224) # 假设输入数据为 1 组,通道数为 3,图像尺寸为 224x224 # 运行 LRN 模块 output = lrn(input_data) print(output.shape) # 输出特征的形状 # torch.Size([1, 3, 224, 224])
51.LSTM: 长短期记忆(LSTM)神经网络层。
是一种常用的循环神经网络(RNN)变体,专门设计用来解决传统 RNN 中遇到的长期依赖问题。LSTM 的设计使其能够更好地捕捉和利用长期序列中的依赖关系,适用于处理时间序列数据、自然语言处理等任务。
Apply a single-layer LSTM to a feature sequence of T timesteps. The input blob shape is [w=input_size, h=T] and the output blob shape is [w=num_output, h=T].
y = lstm(x)
y0, hidden y1, cell y2 = lstm(x0, hidden x1, cell x2)
- one_blob_only if bidirectional
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | output size of output |
| 1 | weight_data_size | int | 0 | total size of IFOG weight matrix |
| 2 | direction | int | 0 | 0=forward, 1=reverse, 2=bidirectional |
| 3 | hidden_size | int | num_output | hidden size |
| weight | type | shape |
|---|---|---|
| weight_xc_data | float/fp16/int8 | [input_size, hidden_size * 4, num_directions] |
| bias_c_data | float/fp16/int8 | [hidden_size, 4, num_directions] |
| weight_hc_data | float/fp16/int8 | [num_output, hidden_size * 4, num_directions] |
| weight_hr_data | float/fp16/int8 | [hidden_size, num_output, num_directions] |
Direction flag:
- 0 = forward only
- 1 = reverse only
- 2 = bidirectional
52.MemoryData: 用于存储数据并生成数据迭代器。
用于在模型中定义一个固定大小的内存数据块。MemoryData 层通常用于存储一些固定的参数或中间数据,以便在模型前向推理过程中进行使用。
y = data
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | w | int | 0 | |
| 1 | h | int | 0 | |
| 11 | d | int | 0 | |
| 2 | c | int | 0 | |
| 21 | load_type | int | 1 | 1=fp32 |
| weight | type | shape |
|---|---|---|
| data | float | [w, h, d, c] |
53.Mish: 应用Mish激活函数。
Mish 激活函数的形式相对简单,但由于其使用了双曲正切函数和软加函数的组合,可以在一定程度上克服一些常见激活函数的问题,如梯度消失和梯度爆炸。
y = x * tanh(log(exp(x) + 1))
- one_blob_only
- support_inplace
54.MultiHeadAttention: 多头注意力机制。
多头注意力机制是注意力机制的一种扩展形式,旨在充分利用不同“头”(独立的子空间)来对输入的序列进行不同方式的关注和表示。每个“头”都学习关注输入序列中不同的部分,从而能够更好地捕捉序列中的不同特征和关系。
split q k v into num_head part q0, k0, v0, q1, k1, v1 ...
for each num_head part
xq = affine(q) / (embed_dim / num_head)
xk = affine(k)
xv = affine(v)
xqk = xq * xk
xqk = xqk + attn_mask if attn_mask exists
softmax_inplace(xqk)
xqkv = xqk * xv
merge xqkv to out
y = affine(out)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | embed_dim | int | 0 | |
| 1 | num_heads | int | 1 | |
| 2 | weight_data_size | int | 0 | |
| 3 | kdim | int | embed_dim | |
| 4 | vdim | int | embed_dim | |
| 5 | attn_mask | int | 0 |
| weight | type | shape |
|---|---|---|
| q_weight_data | float/fp16/int8 | [weight_data_size] |
| q_bias_data | float | [embed_dim] |
| k_weight_data | float/fp16/int8 | [embed_dim * kdim] |
| k_bias_data | float | [embed_dim] |
| v_weight_data | float/fp16/int8 | [embed_dim * vdim] |
| v_bias_data | float | [embed_dim] |
| out_weight_data | float/fp16/int8 | [weight_data_size] |
| out_bias_data | float | [embed_dim] |
55.MVN: 均值方差归一化操作。
if normalize_variance == 1 && across_channels == 1 y = (x - mean) / (sqrt(var) + eps) of whole blob
if normalize_variance == 1 && across_channels == 0 y = (x - mean) / (sqrt(var) + eps) of each channel
if normalize_variance == 0 && across_channels == 1 y = x - mean of whole blob
if normalize_variance == 0 && across_channels == 0 y = x - mean of each channel
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | normalize_variance | int | 0 | |
| 1 | across_channels | int | 0 | |
| 2 | eps | float | 0.0001f | x = x / (sqrt(var) + eps) |
56.Noop: 空操作
空操作,不对输入做任何操作
y = x57.Normalize: 归一化操作
对输入数据进行归一化操作
if across_spatial == 1 && across_channel == 1 x2 = normalize(x) of whole blob
if across_spatial == 1 && across_channel == 0 x2 = normalize(x) of each channel
if across_spatial == 0 && across_channel == 1 x2 = normalize(x) of each position
y = x2 * scale
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | across_spatial | int | 0 | |
| 1 | channel_shared | int | 0 | |
| 2 | eps | float | 0.0001f | see eps mode |
| 3 | scale_data_size | int | 0 | |
| 4 | across_channel | int | 0 | |
| 9 | eps_mode | int | 0 |
| weight | type | shape |
|---|---|---|
| scale_data | float | [scale_data_size] |
Eps Mode:
- 0 = caffe/mxnet x = x / sqrt(var + eps)
- 1 = pytorch x = x / max(sqrt(var), eps)
- 2 = tensorflow x = x / sqrt(max(var, eps))
58.Packing: 打包操作
用于高效处理图像张量数据
y = wrap_packing(x)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | out_elempack | int | 1 | |
| 1 | use_padding | int | 0 | |
| 2 | cast_type_from | int | 0 | |
| 3 | cast_type_to | int | 0 | |
| 4 | storage_type_from | int | 0 | |
| 5 | storage_type_to | int | 0 |
59.Padding: 填充操作
对输入数据进行填充操作
y = pad(x, pads)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | top | int | 0 | |
| 1 | bottom | int | 0 | |
| 2 | left | int | 0 | |
| 3 | right | int | 0 | |
| 4 | type | int | 0 | |
| 5 | value | float | 0 | |
| 6 | per_channel_pad_data_size | int | 0 | |
| 7 | front | int | stride_w | |
| 8 | behind | int | pad_left |
| weight | type | shape |
|---|---|---|
| per_channel_pad_data | float | [per_channel_pad_data_size] |
Padding type:
- 0 = CONSTANT
- 1 = REPLICATE
- 2 = REFLECT
60.Permute: 置换操作
对输入数据的维度进行排列操作
指的是重新排列数据或张量中的维度,以改变数据的排列顺序或维度顺序。这样的操作可以对数据进行重构以适应不同的模型或算法的需求,也可以在处理序列数据时对特定维度进行调整。
y = reorder(x)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | order_type | int | 0 |
Order Type:排列类型如下( W-宽 H-高 C-通道 D-深度)
- 0 = WH WHC WHDC
- 1 = HW HWC HWDC
- 2 = WCH WDHC
- 3 = CWH DWHC
- 4 = HCW HDWC
- 5 = CHW DHWC
- 6 = WHCD
- 7 = HWCD
- 8 = WCHD
- 9 = CWHD
- 10 = HCWD
- 11 = CHWD
- 12 = WDCH
- 13 = DWCH
- 14 = WCDH
- 15 = CWDH
- 16 = DCWH
- 17 = CDWH
- 18 = HDCW
- 19 = DHCW
- 20 = HCDW
- 21 = CHDW
- 22 = DCHW
- 23 = CDHW
61.PixelShuffle: 像素重组
执行像素重排操作,用于实现像素重排。这种操作通常用于超分辨率重建或者图像生成领域
if mode == 0 y = depth_to_space(x) where x channel order is sw-sh-outc
if mode == 1 y = depth_to_space(x) where x channel order is outc-sw-sh
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | upscale_factor | int | 1 | |
| 1 | mode | int | 0 |
PixelShuffle 操作将输入张量中的通道分组,然后对每个分组内的像素进行重排,从而增加图像的分辨率。在每个分组内部,PixelShuffle 操作会将多个低分辨率通道重组成一个高分辨率通道。
PixelShuffle 的主要优点是可以在不引入额外参数的情况下增加图像的分辨率,这使得神经网络在图像超分辨率重建等任务上表现更加出色
62.Pooling: 池化操作
执行池化操作,降低特征图维度
x2 = pad(x, pads)
x3 = pooling(x2, kernel, stride)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | pooling_type | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | stride_w | int | 1 | |
| 3 | pad_left | int | 0 | |
| 4 | global_pooling | int | 0 | |
| 5 | pad_mode | int | 0 | |
| 6 | avgpool_count_include_pad | int | 0 | |
| 7 | adaptive_pooling | int | 0 | |
| 8 | out_w | int | 0 | |
| 11 | kernel_h | int | kernel_w | |
| 12 | stride_h | int | stride_w | |
| 13 | pad_top | int | pad_left | |
| 14 | pad_right | int | pad_left | |
| 15 | pad_bottom | int | pad_top | |
| 18 | out_h | int | out_w |
Pooling type:
- 0 = MAX
- 1 = AVG
Pad mode:
- 0 = full padding
- 1 = valid padding
- 2 = tensorflow padding=SAME or onnx padding=SAME_UPPER
- 3 = onnx padding=SAME_LOWER
63.Pooling1D: 一维池化操作
在一维数据上执行池化操作
x2 = pad(x, pads)
x3 = pooling1d(x2, kernel, stride)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | pooling_type | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | stride_w | int | 1 | |
| 3 | pad_left | int | 0 | |
| 4 | global_pooling | int | 0 | |
| 5 | pad_mode | int | 0 | |
| 6 | avgpool_count_include_pad | int | 0 | |
| 7 | adaptive_pooling | int | 0 | |
| 8 | out_w | int | 0 | |
| 14 | pad_right | int | pad_left |
Pooling type:
- 0 = MAX
- 1 = AVG
Pad mode:
- 0 = full padding
- 1 = valid padding
- 2 = tensorflow padding=SAME or onnx padding=SAME_UPPER
- 3 = onnx padding=SAME_LOWER
64.Pooling3D: 三维池化操作
在三维数据上执行池化操作
x2 = pad(x, pads)
x3 = pooling3d(x2, kernel, stride)
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | pooling_type | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | stride_w | int | 1 | |
| 3 | pad_left | int | 0 | |
| 4 | global_pooling | int | 0 | |
| 5 | pad_mode | int | 0 | |
| 6 | avgpool_count_include_pad | int | 0 | |
| 7 | adaptive_pooling | int | 0 | |
| 8 | out_w | int | 0 | |
| 11 | kernel_h | int | kernel_w | |
| 12 | stride_h | int | stride_w | |
| 13 | pad_top | int | pad_left | |
| 14 | pad_right | int | pad_left | |
| 15 | pad_bottom | int | pad_top | |
| 16 | pad_behind | int | pad_front | |
| 18 | out_h | int | out_w | |
| 21 | kernel_d | int | kernel_w | |
| 22 | stride_d | int | stride_w | |
| 23 | pad_front | int | pad_left | |
| 28 | out_d | int | out_w |
Pooling type:
- 0 = MAX
- 1 = AVG
Pad mode:
- 0 = full padding
- 1 = valid padding
- 2 = tensorflow padding=SAME or onnx padding=SAME_UPPER
- 3 = onnx padding=SAME_LOWER
65.Power: 幂运算
对输入数据执行幂运算
y = pow((shift + x * scale), power)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | power | float | 1.f | |
| 1 | scale | float | 1.f | |
| 2 | shift | float | 0.f |
66.PReLU: 参数化修正线性单元
在传统的ReLU中,当输入值小于0时,激活函数的输出始终为0。而在PReLU中,当输入值小于0时,激活函数的输出不再是固定的0,而是一个小的线性函数,其斜率是可学习的参数,即一个非零值
if x < 0 y = x * slope
else y = x
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_slope | int | 0 |
| weight | type | shape |
|---|---|---|
| slope_data | float | [num_slope] |
67.Quantize: 量化操作
量化是将神经网络中的参数和/或激活值从较高精度(比如32位浮点数)转换为较低精度(比如8位整数)的过程。这一过程有助于减少模型的存储消耗和计算成本,并且在一定程度上可以提高模型的运行速度
y = float2int8(x * scale)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | scale_data_size | int | 1 |
| weight | type | shape |
|---|---|---|
| scale_data | float | [scale_data_size] |
68.Reduction: 执行张量的降维操作
进行聚合操作或降维操作
y = reduce_op(x * coeff)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | operation | int | 0 | |
| 1 | reduce_all | int | 1 | |
| 2 | coeff | float | 1.f | |
| 3 | axes | array | [ ] | |
| 4 | keepdims | int | 0 | |
| 5 | fixbug0 | int | 0 | hack for bug fix, should be 1 |
Operation type:
- 0 = SUM (求和):将张量中所有元素相加,得到一个标量值。
- 1 = ASUM(绝对值求和): 将张量中所有元素的绝对值相加,得到一个标量值。
- 2 = SUMSQ (平方和): 将张量中所有元素的平方相加,得到一个标量值。
- 3 = MEAN (均值): 计算张量中所有元素的平均值,得到一个标量值
- 4 = MAX (最大值): 找出张量中的最大值,并返回一个标量值。
- 5 = MIN(最小值): 找出张量中的最小值,并返回一个标量值。
- 6 = PROD(乘积): 计算张量中所有元素的乘积,得到一个标量值。
- 7 = L1 (L1范数):计算张量中所有元素的L1范数(绝对值的和),得到一个标量值。
- 8 = L2(L2范数): 计算张量中所有元素的L2范数(平方和后开根号),得到一个标量值。
- 9 = LogSum(对数求和): 对张量中的元素取对数后相加,得到一个标量值。
- 10 = LogSumExp对数指数求和): 对张量中的元素先分别取指数,再取对数后相加,得到一个标量值。
69.ReLU: 应用修正线性单元(ReLU)激活函数。
ReLU函数对输入值进行处理,如果输入值小于零,则输出为零;如果输入值大于零,则输出与输入相同
if x < 0 y = x * slope
else y = x
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | slope | float | 0.f |
70.Reorg: 通道重排操作
将输入张量的通道重新排列,实现通道数变化和数据重组,从而满足特定的网络结构要求。通常情况下,Reorg操作会改变张量的通道数、高度和宽度,同时保持数据不变
if mode == 0 y = space_to_depth(x) where x channel order is sw-sh-outc
if mode == 1 y = space_to_depth(x) where x channel order is outc-sw-sh
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | stride | int | 1 | |
| 1 | mode | int | 0 |
71.Requantize: 重新量化(再量化)
就是对量化的数据进再量化,一般Quantize从f32 到 int8 ,Requantize 从int32 到int8
x2 = x * scale_in + bias
x3 = activation(x2)
y = float2int8(x3 * scale_out)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | scale_in_data_size | int | 1 | |
| 1 | scale_out_data_size | int | 1 | |
| 2 | bias_data_size | int | 0 | |
| 3 | activation_type | int | 0 | |
| 4 | activation_params | int | [ ] |
| weight | type | shape |
|---|---|---|
| scale_in_data | float | [scale_in_data_size] |
| scale_out_data | float | [scale_out_data_size] |
| bias_data | float | [bias_data_size] |
72.Reshape: 形状重塑操作
对输入数据进行形状重塑操作
操作通常用于调整神经网络中层的输入输出张量的形状,以适应不同层之间的连接需求或更改数据的维度
if permute == 1 y = hwc2chw(reshape(chw2hwc(x)))
else y = reshape(x)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | w | int | -233 | |
| 1 | h | int | -233 | |
| 11 | d | int | -233 | |
| 2 | c | int | -233 | |
| 3 | permute | int | 0 |
Reshape flag:
- 0 = copy from bottom (当维度值为0时,表示从底部(原始维度)复制维度值。换句话说,保留原始张量的相应维度值)
- -1 = remaining (维度值为-1时,表示保持剩余的维度不变。这意味着在进行reshape操作时,会根据其他指定的维度值,自动计算并保持剩余的维度值)
- -233 = drop this dim(default)(维度值为-233时,表示丢弃该维度。在进行reshape操作时,将会将指定维度值设为-233,这样就会将该维度丢弃,从而改变张量的形状)
73.RNN: 循环神经网络(RNN)层。
Apply a single-layer RNN to a feature sequence of T timesteps. The input blob shape is [w=input_size, h=T] and the output blob shape is [w=num_output, h=T].
将单层 RNN 应用于一个包含 T 个时间步的特征序列。输入的数据形状为 [w=input_size, h=T],输出的数据形状为 [w=num_output, h=T]。
y = rnn(x)
y0, hidden y1 = rnn(x0, hidden x1)
- one_blob_only if bidirectional
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | hidden size of output |
| 1 | weight_data_size | int | 0 | total size of weight matrix |
| 2 | direction | int | 0 | 0=forward, 1=reverse, 2=bidirectional |
| weight | type | shape |
|---|---|---|
| weight_xc_data | float/fp16/int8 | [input_size, num_output, num_directions] |
| bias_c_data | float/fp16/int8 | [num_output, 1, num_directions] |
| weight_hc_data | float/fp16/int8 | [num_output, num_output, num_directions] |
Direction flag:
- 0 = forward only 只允许向前移动
- 1 = reverse only 只允许向后移动
- 2 = bidirectional 允许双向移动
74.Scale: 缩放操作
操作通常用于调整权重、偏置或特征图等参数的数值大小,以影响模型的学习效率、性能和收敛速度
if scale_data_size == -233 y = x0 * x1
else y = x * scale + bias
- one_blob_only if scale_data_size != -233
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | scale_data_size | int | 0 | |
| 1 | bias_term | int | 0 |
| weight | type | shape |
|---|---|---|
| scale_data | float | [scale_data_size] |
| bias_data | float | [scale_data_size] |
75.SELU: 应用自归一化激活函数
是一种激活函数。SELU激活函数最初由Hochreiter等人在2017年提出,被设计用于神经网络的隐藏层,与其他激活函数(如ReLU、sigmoid、tanh)相比,SELU具有一些独特的性质和优势。

= 1.0507 和
= 1.67326
SELU激活函数具有以下特点:
-
自归一化性质(self-normalizing): 在一定条件下,使用SELU激活函数可以使得神经网络自我归一化,有助于缓解梯度消失或爆炸问题,提高网络训练的稳定性。
-
非线性特性: SELU在激活过程中引入了非线性,有助于神经网络学习复杂的数据模式和特征。
-
稳定性和鲁棒性: SELU对于输入值的变化相对稳定,在一定程度上增强了网络的鲁棒性。
if x < 0 y = (exp(x) - 1.f) * alpha * lambda
else y = x * lambda
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | alpha | float | 1.67326324f | |
| 1 | lambda | float | 1.050700987f |
76.Shrink: 对输入数据进行收缩操作
操作通常用于减少量化后张量数据的尺寸,以便在神经网络计算中更有效地处理数据
if x < -lambd y = x + bias
if x > lambd y = x - bias
else y = x
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | bias | float | 0.0f | |
| 1 | lambd | float | 0.5f |
77.ShuffleChannel: 通道混洗操作
会将输入张量的通道进行重新排列,以改变数据的通道顺
- 将输入张量按照一定规则分割成若干个通道组。
- 对这些通道组进行重新排列。
- 将重新排列后的通道重新组合成最终的输出张量。
if reverse == 0 y = shufflechannel(x) by group
if reverse == 1 y = shufflechannel(x) by channel / group
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | group | int | 1 | |
| 1 | reverse | int | 0 |
78.Sigmoid: 应用Sigmoid激活函数
它将任意实数映射到一个取值范围在 0 到 1 之间的实数
Sigmoid函数曾经被广泛用于隐藏层的激活函数,但后来由于存在梯度消失和饱和性的问题,逐渐被ReLU等激活函数取代
y = 1 / (1 + exp(-x))
- one_blob_only
- support_inplace
79.Slice: 分割操作
操作通常用于从输入张量中获取指定范围内的子张量或子数组。
Slice操作可以根据用户指定的起始索引和结束索引以及步长,从输入张量中提取出一个子张量。这个子张量通常是原始张量的一个子集,用于在神经网络中的特定层或模块中进一步处理
split x along axis into slices, each part slice size is based on slices array
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | slices | array | [ ] | 切片数组 |
| 1 | axis | int | 0 | 轴 |
| 2 | indices | array | [ ] |
80.Softmax: 应用Softmax激活函数,通常用于分类任务。
将模型的原始输出转换为表示概率分布的形式
softmax(x, axis)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | axis | int | 0 | |
| 1 | fixbug0 | int | 0 | hack for bug fix, should be 1 |
import torch
import torch.nn.functional as F
# 定义一个示例原始输出张量
logits = torch.tensor([2.0, 1.0, 0.1])
# 使用 torch.nn.functional.softmax 进行Softmax操作
probabilities = F.softmax(logits, dim=0)
# 打印转换后的概率分布
print("Softmax输出概率分布:")
print(probabilities)
# Softmax输出概率分布:
# tensor([0.6590, 0.2424, 0.0986])81.Softplus: 应用Softplus激活函数。
softplus(x)=log(1+ex)
Softplus函数可以将输入的任何实数映射到一个大于零的实数范围内
Softplus函数的特点是它在输入值为负数时会接近于0,而在输入值为正数时会保持增长。与 ReLU 函数类似,Softplus函数也具有非线性特性,有助于增加神经网络的表达能力
y = log(exp(x) + 1)
- one_blob_only
- support_inplace
-
import torch import torch.nn.functional as F # 定义一个示例输入张量 x = torch.tensor([-2.0, 0.0, 2.0]) # 使用 torch.nn.functional.softplus 进行Softplus操作 output = F.softplus(x) # 打印Softplus函数的输出 print("Softplus输出:") print(output) # Softplus输出: # tensor([0.1269, 0.6931, 2.1269])
82.Split: 将输入数据分割为多个部分。
直接把输入数据复制多份,此处应该直接就是指针引用
y0, y1 ... = x83.Swish: swish激活函数
应用Swish激活函数
y = x / (1 + exp(-x))- one_blob_only
- support_inplace
84.TanH: TanH激活函数
应用双曲正切(tanh)激活函数
y = tanh(x)
- one_blob_only
- support_inplace
85.Threshold: 阈值操作
对输入数据应用阈值操作
if x > threshold y = 1
else y = 0
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | threshold | float | 0.f |
86.Tile: 重复复制
是指在张量的维度上重复其内容以扩展张量的尺寸。重复操作允许您在指定的维度上复制张量中的数据,从而增加该维度的大小。
y = repeat tiles along axis for x
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | axis | int | 0 | 轴 |
| 1 | tiles | int | 1 | 次数 |
| 2 | repeats | array | [ ] |
import torch
# 创建一个示例张量
x = torch.tensor([[1, 2],
[3, 4]])
# 定义参数
params = {"axis": 0, "tiles": 2, "repeats": [2, 1]}
# 获取参数值
axis = params["axis"]
tiles = params["tiles"]
repeats = params["repeats"]
# 在指定的轴上重复张量内容
y = x.repeat(repeats[0] if axis == 0 else 1, repeats[1] if axis == 1 else 1)
# 输出结果
print(y)
# tensor([[1, 2],
# [3, 4],
# [1, 2],
# [3, 4]])87.UnaryOp: 对输入执行一元操作。
一元操作通常涉及对输入进行转换、变换或提取特定信息,而不涉及多个输入之间的操作
y = unaryop(x)
- one_blob_only
- support_inplace
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | op_type | int | 0 | Operation type as follows |
Operation type:
- 0 = ABS(绝对值):返回输入的绝对值。
- 1 = NEG(负值):返回输入的负值。
- 2 = FLOOR(向下取整):返回不大于输入值的最大整数。
- 3 = CEIL(向上取整):返回不小于输入值的最小整数
- 4 = SQUARE(平方):返回输入值的平方。
- 5 = SQRT(平方根):返回输入的平方根。
- 6 = RSQ(倒数平方根):返回输入值的倒数的平方根。
- 7 = EXP(指数):返回以 e 为底的输入值的指数。
- 8 = LOG(对数):返回输入值的自然对数。
- 9 = SIN(正弦):返回输入值的正弦值。
- 10 = COS(余弦):返回输入值的余弦值。
- 11 = TAN(正切):返回输入值的正切值。
- 12 = ASIN(反正弦):返回输入值的反正弦值
- 13 = ACOS(反余弦):返回输入值的反余弦值。
- 14 = ATAN(反正切):返回输入值的反正切值。
- 15 = RECIPROCAL(倒数):返回输入值的倒数。
- 16 = TANH(双曲正切):返回输入值的双曲正切值。
- 17 = LOG10(以10为底的对数):返回输入值的以10为底的对数。
- 18 = ROUND(四舍五入):返回输入值四舍五入的结果。
- 19 = TRUNC(截断):返回输入值的整数部分。
88.Unfold: 在输入数据上执行展开操作。
从一个批次的输入张量中提取出滑动的局部区域块
y = unfold(x)
- one_blob_only
| param id | name | type | default | description |
|---|---|---|---|---|
| 0 | num_output | int | 0 | |
| 1 | kernel_w | int | 0 | |
| 2 | dilation_w | int | 1 | |
| 3 | stride_w | int | 1 | |
| 4 | pad_left | int | 0 | |
| 11 | kernel_h | int | kernel_w | |
| 12 | dilation_h | int | dilation_w | |
| 13 | stride_h | int | stride_w | |
| 14 | pad_top | int | pad_left | |
| 15 | pad_right | int | pad_left | |
| 16 | pad_bottom | int | pad_top |
import torch
# 创建一个3x3的张量作为示例输入
input_tensor = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 在第一个维度上展开,窗口大小为2,步长为1
unfolded_tensor = input_tensor.unfold(0, 2, 1)
print('Input Tensor:\n', input_tensor)
# tensor([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
print('Unfolded Tensor:\n', unfolded_tensor,"\nshape:",unfolded_tensor.shape)
# tensor([[[1, 4],
# [2, 5],
# [3, 6]],
#
# [[4, 7],
# [5, 8],
# [6, 9]]])
# shape: torch.Size([2, 3, 2])



![[激光原理与应用-92]:振镜的光路图原理](https://img-blog.csdnimg.cn/img_convert/c396306338f263636a14e845c8e568a1.png)